.webp)
Muchas empresas no tienen un problema de datos. Tienen un problema de fundamentos.
Crecen, venden más, suman clientes, pero algo empieza a romperse. Los procesos se vuelven lentos, los números no coinciden entre áreas y los sistemas dejan de “hablarse” entre sí. Y casi siempre aparece la misma frase: “luego lo arreglamos”.
El problema es que ese “luego” llega en el peor momento: cuando crecer ya no se siente como un avance, sino como una fricción que puede ser operativa, técnica y financiera.
Ahí es donde entra la arquitectura de datos.
No es algo visible en el día a día, pero sostiene absolutamente todo: desde cómo se toman decisiones hasta qué tan rápido puede moverse una empresa.
En BluePixel ponemos este tema sobre la mesa por una razón clara: hemos visto que la diferencia entre empresas que solo crecen y empresas que realmente escalan no está en cuántos datos tienen, sino en cómo lo estructuran.
En este artículo te explicamos qué es una arquitectura de datos escalable y, más importante, cómo saber si tu empresa está lista para crecer sin que sus propios sistemas se conviertan en un obstáculo.

Primero lo primero: ¿qué es una arquitectura de datos escalable?
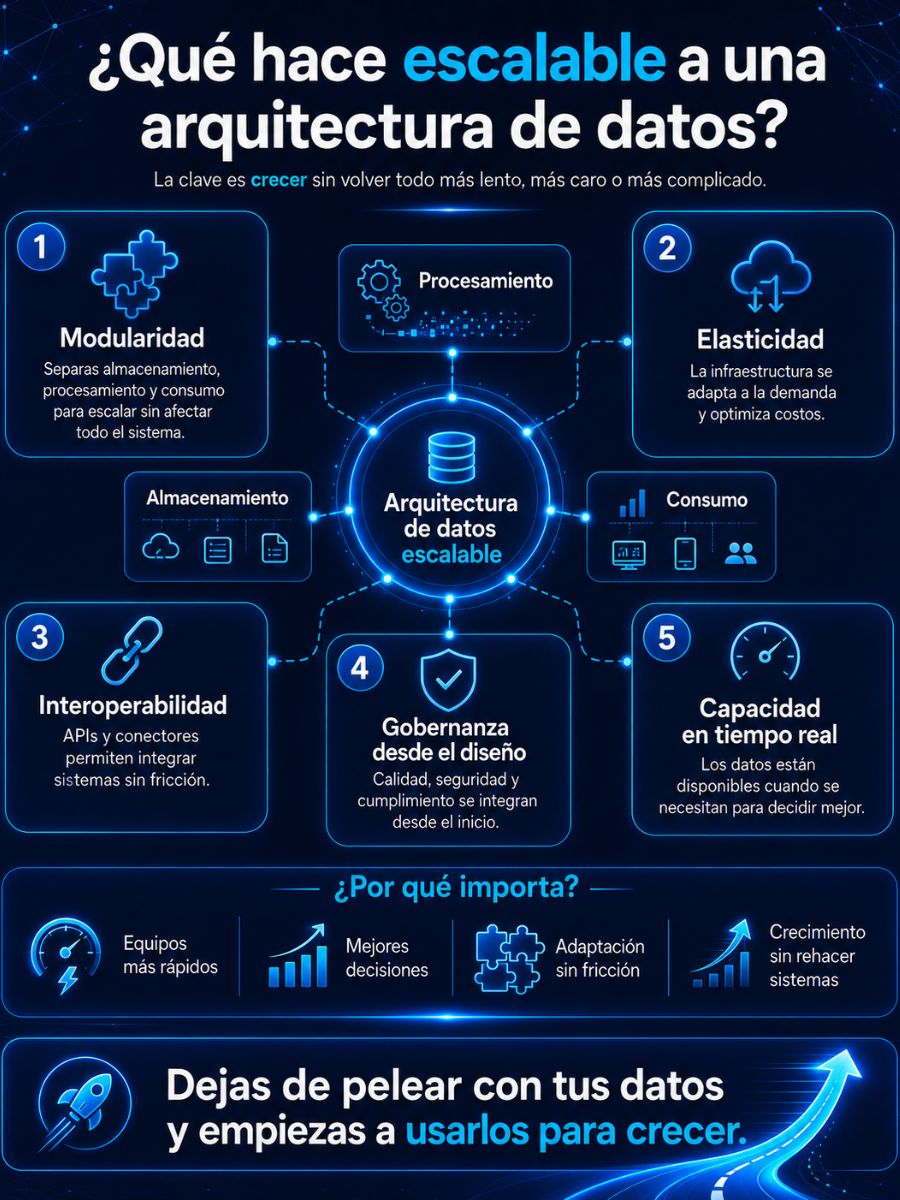
Una arquitectura de datos escalable es la forma en que organizas y conectas tus datos para que tu empresa pueda crecer sin que todo se vuelva más lento, más caro o más complicado. El objetivo es no tener que reconstruir tu sistema cada vez que agregas más información, herramientas o usuarios.
Para lograrlo, hay principios que no son negociables:
- Modularidad
No todo está conectado de forma rígida. Separas almacenamiento, procesamiento y consumo de datos para poder escalar o modificar partes sin afectar todo el sistema. - Elasticidad
Tu infraestructura se adapta a la demanda. Escalas cuando necesitas y optimizas costos cuando no. Esto es especialmente relevante en entornos de nube. - Interoperabilidad
Tus sistemas pueden integrarse sin fricción. APIs, conectores y estándares abiertos evitan depender de soluciones cerradas o integraciones frágiles. - Gobernanza desde el diseño
Calidad, seguridad y cumplimiento no se agregan después. Están integrados desde el inicio para evitar errores, inconsistencias y riesgos. - Capacidad en tiempo real
No esperas días para tomar decisiones. Los datos están disponibles cuando los necesitas, no cuando el sistema los permite.
¿Y por qué importan estos principios? Porque, si tu arquitectura está bien diseñada, tus equipos pueden trabajar más rápido, tomar mejores decisiones y adaptarse sin fricción. No necesitas rehacer tus sistemas cada vez que tu negocio cambia o crece.
En resumen: dejas de pelear con tus datos y empiezas a usarlos para crecer.
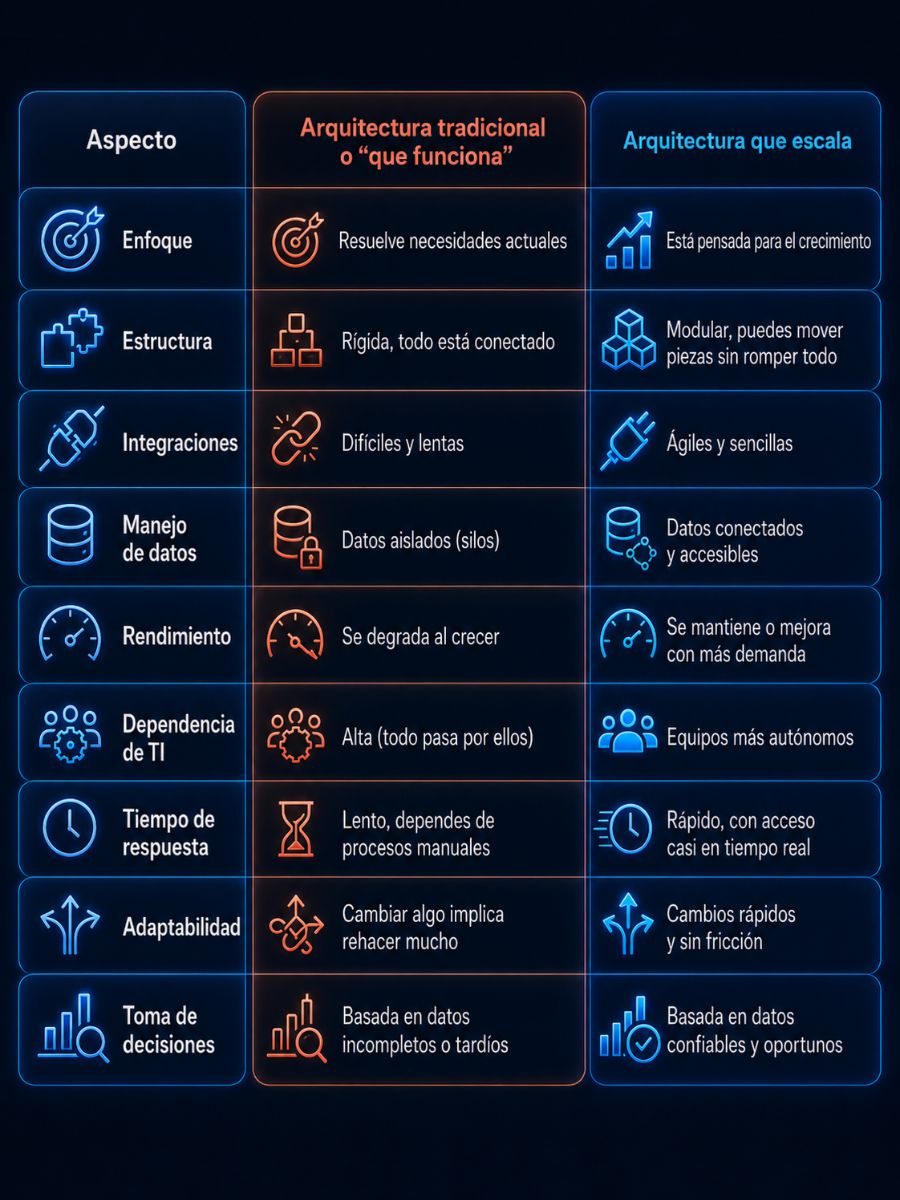
Arquitectura de datos tradicional vs arquitectura de datos escalable
Muchas empresas operan durante años con arquitecturas que “funcionan”, pero que no fueron diseñadas para crecer. La diferencia entre una arquitectura tradicional y una escalable no siempre es evidente al inicio, pero se vuelve crítica conforme el negocio evoluciona.
Una arquitectura tradicional suele ser rígida. Los sistemas están fuertemente acoplados, lo que hace que cualquier cambio implique tocar múltiples componentes. Esto limita la flexibilidad y hace que adaptarse a nuevas necesidades sea lento y costoso. En contraste, una arquitectura escalable está diseñada para evolucionar: separa responsabilidades, permite integrar nuevas tecnologías y se adapta sin rehacer todo el sistema.
En términos de costos, la diferencia también es significativa. Las arquitecturas tradicionales tienden a generar gastos crecientes conforme aumenta la complejidad, mientras que una arquitectura moderna optimiza recursos, especialmente en entornos de nube donde se puede escalar bajo demanda.
El tiempo de respuesta es otro punto crítico. En modelos tradicionales, los datos suelen procesarse con retraso, lo que limita la capacidad de reacción del negocio. En una arquitectura escalable, el acceso a información es mucho más ágil, incluso cercano al tiempo real.
Pero quizá la diferencia más importante está en el impacto en el negocio. Una arquitectura tradicional limita la velocidad de decisión y la capacidad de innovación. Una arquitectura escalable, en cambio, habilita crecimiento, experimentación y adaptación constante.
La siguiente tabla resume de forma clara esas diferencias y por qué no es lo mismo operar “bien” que estar listo para crecer:
Lo más importante que debes saber: la arquitectura de datos define la capacidad de crecimiento de tu negocio
La arquitectura de datos define qué tan rápido puede operar una empresa porque conecta tres cosas clave: datos, decisiones y velocidad. Esto se ve en situaciones muy concretas del día a día. Por ejemplo, en operaciones, cuando los inventarios, las ventas y la logística no están sincronizados, puedes terminar vendiendo productos que ya no tienes o frenando pedidos que sí podrías cumplir. En finanzas, cuando los números de ingresos no coinciden entre sistemas, los cierres se retrasan y las decisiones se posponen. En desarrollo de producto, si no puedes analizar el comportamiento de los usuarios porque los datos están fragmentados, mejoras lo que “crees” y no lo que realmente pasa. Si los datos no fluyen bien, las decisiones se frenan. Y cuando las decisiones se frenan, el negocio también.
El problema es que estos frenos casi nunca son obvios. Son cuellos de botella invisibles que se vuelven parte de la operación: reportes que hay que consolidar manualmente cada mes, equipos que trabajan con versiones distintas de la misma información, o áreas que dependen de alguien más para obtener datos básicos. Nada colapsa por completo, pero todo toma más tiempo del que debería.
Y ahí aparece el costo oculto de tener una mala arquitectura de datos. No es solo un tema de tecnología, sino uno de negocio: decisiones tardías, errores operativos, retrabajos constantes y oportunidades que se pierden porque reaccionar toma demasiado tiempo. Es crecer, pero con fricción en cada paso.
Por eso, cuando hablamos de arquitectura de datos y crecimiento empresarial, hablamos de la capacidad real de una empresa para moverse con agilidad, adaptarse al cambio y escalar sin que sus propios datos se conviertan en un obstáculo.
>> Podría interesarte leer: Futureproof, el enfoque que te evitará reescribir tu software cada 3 años
Pero, ¿qué pasa si tu arquitectura de datos no está lista para escalar? ¿Cuáles son las señales?
Si tu empresa está creciendo, tu arquitectura de datos debería hacerlo al mismo ritmo. Cuando no pasa, empiezan a aparecer señales muy claras —aunque muchas veces se normalizan— de que algo no está preparado para escalar. Identificar estos síntomas a tiempo puede evitar que los problemas de arquitectura de datos se conviertan en un freno estructural para el negocio.
Una de las primeras señales es el tiempo dedicado a tus procesos
Si los reportes tardan días o incluso semanas en estar listos, no es solo un tema de eficiencia: es un problema de toma de decisiones. Cuando por fin tienes la información, el contexto ya cambió. Esto suele venir acompañado de otra señal crítica…
Cada área maneja “su versión” de los datos
Finanzas, operaciones y producto reportan números distintos en una misma junta, y la conversación se desvía a “cuál es el dato correcto” en lugar de “qué hacemos con él”.
También es común que integrar nuevas herramientas o fuentes de datos se vuelva muy complejo
Lo que debería tomar días se convierte en semanas o meses porque los sistemas no están pensados para conectarse fácilmente. Esto no solo retrasa tus iniciativas, también limita la capacidad de innovar o adaptarse rápido al mercado.
A medida que la empresa crece, otro síntoma empieza a escalar con ella: los errores
Datos duplicados, inconsistencias, fallas en pipelines o reportes que requieren validaciones manuales constantes. No es casualidad, es una señal de que la arquitectura no está diseñada para soportar mayor volumen o complejidad.
Y finalmente, una de las señales más críticas: la analítica deja de acompañar las decisiones
Los equipos terminan operando por intuición o experiencia porque confiar en los datos toma demasiado tiempo o esfuerzo. Cuando llegas a este punto, los datos dejan de ser una ventaja competitiva y se convierten en un obstáculo.
Todas estas señales apuntan a lo mismo: no es que falten datos, es que la base que los soporta no está lista para escalar. Detectarlo a tiempo es el primer paso para corregirlo antes de que impacte directamente en el crecimiento de tu negocio.
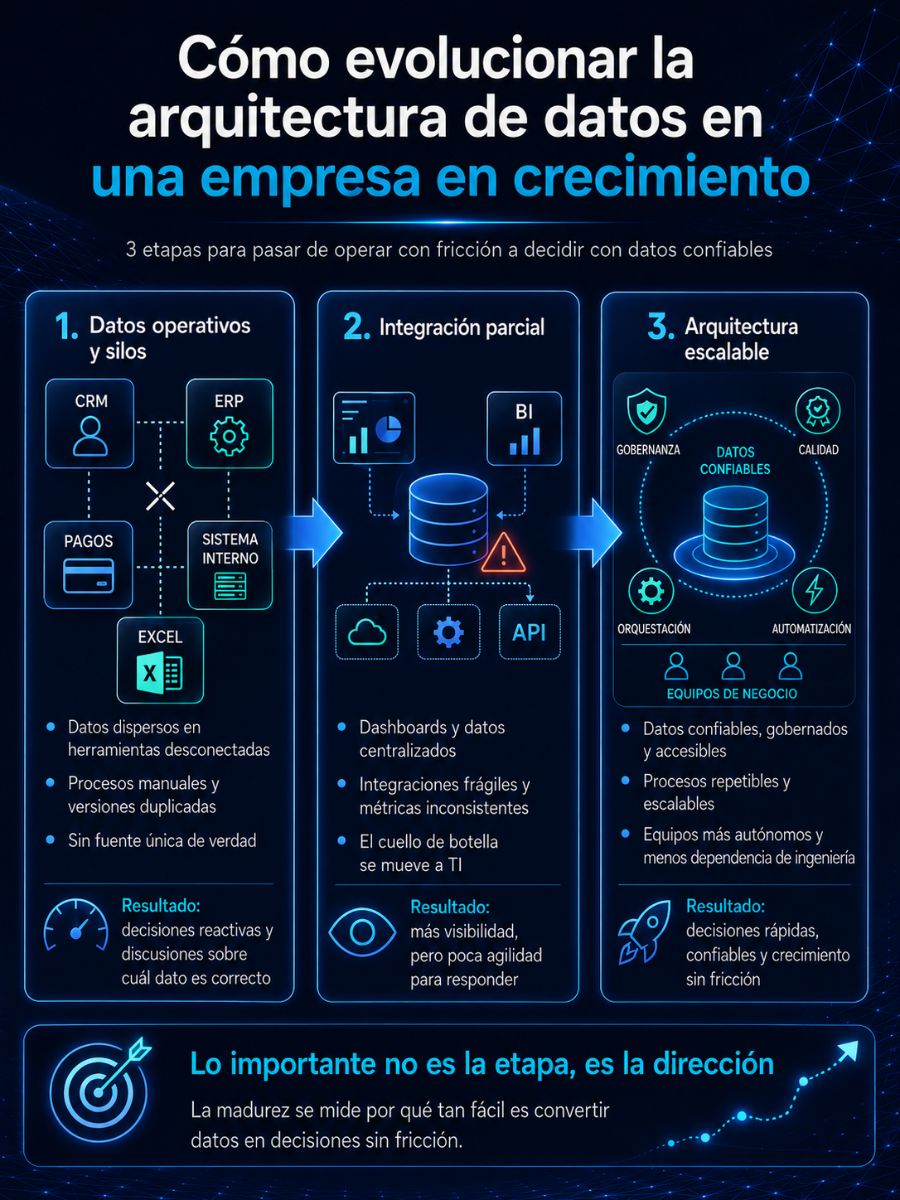
Cómo evolucionar la arquitectura de datos en una empresa en crecimiento
La mayoría de las organizaciones no “diseñan” su arquitectura desde el inicio; la van armando sobre la marcha, conforme surgen necesidades. Al principio, esto es completamente lógico: lo importante es operar, vender y entregar. El problema es que esas decisiones rápidas, que funcionan bien en el corto plazo, se van acumulando hasta convertirse en limitantes estructurales.
Lo interesante es que esta evolución no es caótica. De hecho, sigue un patrón bastante claro. Entender en qué etapa estás no solo te da contexto técnico, también te permite anticipar los siguientes cuellos de botella antes de que empiecen a afectar directamente la operación, los tiempos de respuesta o la calidad de las decisiones.
Etapa 1: datos operativos y silos
Aquí es donde empiezan prácticamente todas las empresas. No hay una intención de diseñar arquitectura, hay una necesidad de resolver el día a día. Los datos viven en múltiples herramientas desconectadas: CRMs, ERPs, plataformas de pago, sistemas internos… y, por supuesto, hojas de cálculo que terminan funcionando como el “pegamento” entre todo.
Cada equipo optimiza para lo suyo. Finanzas tiene su versión de ingresos en Excel, operaciones lleva el control en otro sistema, producto mide el comportamiento en una herramienta distinta. Nadie está “mal”, pero tampoco hay una visión compartida. El concepto de single source of truth simplemente no existe.
En la práctica, esto se traduce en algo muy concreto: exportaciones manuales, archivos que se envían por correo, versiones duplicadas de la misma información y procesos que dependen más de personas que de sistemas. Por ejemplo, es común que alguien tenga que descargar datos de ventas, cruzarlos manualmente con inventario y luego ajustar números para un reporte que, además, alguien más va a reinterpretar en otro archivo.
Aquí aparece el primer problema serio: la confianza en los datos. Cuando en una junta cada área llega con números distintos, la conversación deja de ser estratégica y se convierte en una discusión sobre “quién tiene el dato correcto”.
A nivel negocio, esto obliga a operar de forma reactiva. Se toman decisiones con información incompleta o tardía, y aunque esto puede funcionar cuando el volumen es bajo, deja de ser viable en cuanto la empresa crece. Cada nuevo canal, producto o mercado no suma linealmente: multiplica la complejidad.
Etapa 2: integración parcial
En algún punto, el desorden deja de ser manejable. Los reportes no cuadran, los cierres financieros se retrasan o los equipos pasan más tiempo preparando datos que analizándolos. Es ahí donde las empresas empiezan a “ordenar” su información.
Aparecen herramientas de BI como Tableau o Power BI, que permiten centralizar los dashboards. También se implementan pipelines con herramientas como Fivetran o Talend, y los datos empiezan a consolidarse en warehouses como Google BigQuery o Amazon Redshift.
Desde fuera, parece que el problema está resuelto. Hay dashboards > hay datos centralizados > hay visibilidad. Pero internamente empiezan a aparecer nuevas fricciones.
Los pipelines funcionan, pero son frágiles. Cada integración responde a una necesidad puntual, no a un diseño global. La lógica de negocio está dispersa: una métrica puede calcularse distinto en cada dashboard. Y, sobre todo, no hay un modelo claro de gobierno de datos: nadie define oficialmente qué significa cada indicador, quién es responsable o qué nivel de calidad se espera.
Aquí ocurre algo muy interesante: el cuello de botella no desaparece, se mueve.
Antes el problema era la falta de datos; ahora el problema es la dependencia del equipo técnico para acceder a ellos. El negocio quiere velocidad, pero la arquitectura no está diseñada para responder rápido.
Un ejemplo muy común: un área necesita un nuevo indicador para tomar decisiones semanales. En teoría, los datos existen. En la práctica, hay que pedirlo a ingeniería, priorizarlo en backlog, construirlo, validarlo… y cuando finalmente llega, la necesidad ya cambió o perdió urgencia.
Aunque los datos ya están “centralizados”, no necesariamente están bien modelados. Sin capas semánticas claras o sin buenas prácticas como usar el modelado analítico estructurado, los dashboards pueden seguir mostrando versiones distintas de la misma realidad.
En esta etapa, muchas empresas creen que ya resolvieron su problema de datos. En realidad, lo hicieron más visible.
Etapa 3: arquitectura escalable
Aquí es donde ocurre el cambio de fondo. La empresa deja de construir soluciones aisladas y empieza a diseñar un sistema de datos con intención: pensando no solo en lo que necesita hoy, sino en cómo va a evolucionar.
Los datos se centralizan en plataformas modernas como Snowflake o entornos lakehouse como Databricks, donde el almacenamiento y el cómputo están desacoplados. Esto permite escalar sin rehacer la infraestructura cada vez que aumenta la demanda.
Los pipelines dejan de ser scripts sueltos y pasan a ser procesos orquestados con herramientas como Apache Airflow o Prefect. Se adopta el proceso Extract, Load, and Transform (ELT por sus siglas en inglés) sobre el proceso Extract, Transform, and Load (ETL), aprovechando la capacidad de procesamiento del warehouse.
La transformación de datos se estandariza con herramientas como dbt (data build tool), donde la lógica se vuelve versionable, comprobable y mantenible. Esto cambia completamente la forma en que los equipos trabajan con datos.
A nivel de gobernanza, la conversación madura. Ya no se trata solo de tener datos, sino de poder confiar en ellos. Aparecen definiciones unificadas de métricas, propiedad (ownership) por dominio, validaciones automáticas de calidad y visibilidad sobre el linaje de datos.
También empiezan a adoptarse enfoques más avanzados como data mesh o data fabric, donde los equipos de negocio dejan de ser solo consumidores y pasan a ser responsables de sus propios datos como productos.
El impacto no es solo técnico, es organizacional.
Los equipos pueden explorar datos sin depender constantemente de ingeniería. Integrar una nueva fuente deja de ser un proyecto largo y se convierte en un proceso repetible. Las decisiones se toman con información confiable y en tiempos mucho más cortos.
Y aquí es donde aparece el verdadero cambio: la empresa deja de reaccionar y empieza a anticipar. Puede experimentar más rápido, detectar oportunidades antes y adaptarse sin fricción.
Lo importante no es la etapa, es la dirección
Ninguna empresa empieza en la etapa 3, y no todas necesitan llegar al mismo nivel de sofisticación al mismo tiempo. El problema no es estar en una etapa temprana, es quedarse ahí cuando el negocio ya exige algo distinto.
La arquitectura de datos no es un proyecto que se “termina”, es una capacidad que se construye. Y cada decisión —desde trabajar en hojas de cálculo hasta elegir entre Snowflake o Databricks— tiene impacto directo en la velocidad, eficiencia y capacidad de crecimiento de la empresa.
Al final, la madurez de tu arquitectura no se mide por las herramientas que usas, sino por algo mucho más simple: qué tan fácil es convertir datos en decisiones sin fricción.
Componentes clave de una arquitectura de datos escalable
Una arquitectura de datos escalable no se trata de elegir una herramienta “correcta”, sino de cómo se conectan todas las piezas para que los datos fluyan sin problemas. Es un sistema completo, donde cada capa cumple una función específica y, más importante aún, está pensada para evolucionar.
Todo comienza con las fuentes de datos, que en la práctica son mucho más diversas de lo que parece. No solo hablamos de sistemas internos como CRMs o ERPs, sino también de plataformas externas, integraciones con socios, eventos en tiempo real y datos no estructurados como logs o comportamiento de usuarios. El reto aquí no es capturar datos, sino hacerlo de forma consistente y utilizable.
La siguiente capa, de integración y pipelines, es donde muchas arquitecturas fallan. Los procesos ETL o ELT mal diseñados generan retrasos, inconsistencias o dependencia manual. En cambio, cuando esta capa está bien orquestada, los datos fluyen automáticamente, con monitoreo, trazabilidad y resiliencia ante fallos.
Después viene el almacenamiento. Elegir entre un data warehouse, un data lake o un enfoque lakehouse no es solo una decisión técnica, es una decisión de negocio: define qué tan rápido puedes responder preguntas, cuánto cuesta operar y qué tan flexible es tu arquitectura ante cambios.
Encima de esto está el procesamiento y análisis, donde realmente se genera valor. Aquí es donde se decide si tu empresa solo entiende lo que ya pasó o si puede anticipar lo que viene. La diferencia entre batch (lote) y streaming (transmisión), o entre analítica descriptiva y predictiva, impacta directamente en la velocidad de reacción del negocio.
Y finalmente, la capa que muchas veces se subestima: gobernanza y calidad de datos. Sin seguridad, sin control de accesos, sin definiciones claras y sin validaciones automáticas, cualquier arquitectura pierde credibilidad. Y sin confianza en los datos, no hay decisiones confiables.
¿Cómo saber si tu empresa está lista para una arquitectura de datos escalable?
No todas las empresas necesitan escalar su arquitectura al mismo tiempo, pero hay señales claras de cuándo deja de ser opcional:
- Cuando el negocio empieza a depender de la velocidad para competir. Si necesitas reaccionar rápido, probar nuevos modelos o integrar nuevos canales, tu arquitectura tiene que acompañar ese ritmo.
- Cuando los datos dejan de ser informativos y se vuelven operativos. Es decir, cuando las decisiones del día a día dependen directamente de ellos. En ese punto, cualquier retraso o inconsistencia tiene impacto real.
- La cultura. Cuando los equipos cuestionan decisiones con datos, cuando buscan métricas para validar hipótesis, la necesidad de una base sólida se vuelve inevitable.
- El crecimiento. Si sabes que tu volumen de datos, usuarios o complejidad va a aumentar, esperar a que el sistema falle no suele ser la mejor estrategia.
Cómo diseñar una arquitectura de datos escalable paso a paso
Diseñar una arquitectura escalable no es empezar desde cero, sino tomar mejores decisiones sobre lo que ya existe.
1️⃣ Todo empieza con entender el negocio
Qué decisiones necesitan datos, con qué frecuencia y con qué nivel de precisión. Sin esto, cualquier arquitectura corre el riesgo de volverse innecesariamente compleja.
2️⃣ Diagnóstico realista del estado actual
No desde la teoría, sino desde la operación: dónde se rompen los procesos, dónde se pierden datos, dónde se generan retrasos.
A partir de ahí, el diseño debe enfocarse en eliminar la fricción, no en añadir sofisticación. Pensar en crecimiento no significa sobre-ingeniería, significa dejar espacio para evolucionar.
3️⃣ La implementación, idealmente, es incremental
Cambiar todo al mismo tiempo suele generar más problemas de los que resuelve. En cambio, avanzar por capas permite validar, ajustar y generar valor desde etapas tempranas.
4️⃣ Y finalmente, medir
Porque una arquitectura que no se mide no se puede optimizar, y una que no se optimiza se vuelve obsoleta más rápido de lo que parece.
Evita estos errores comunes al intentar escalar tu información
Uno de los errores más costosos es intentar adelantarse demasiado. Implementar soluciones complejas sin una necesidad real genera sistemas difíciles de operar y mantener.
Otro error es crecer sin dirección. Integrar herramientas sin una visión clara termina creando más silos, solo que ahora más sofisticados.
También es común ver decisiones tecnológicas desconectadas del negocio. Elegir herramientas por tendencia y no por necesidad real es una forma rápida de acumular deuda técnica.
Y quizá el más subestimado: ignorar la gobernanza. Sin reglas claras, los datos pierden consistencia, y cuando eso pasa, el problema deja de ser técnico y se vuelve estratégico.
El rol de la automatización y la IA en una arquitectura de datos moderna
La automatización es lo que permite que todo lo anterior funcione de forma consistente. Sin ella, cualquier arquitectura depende demasiado de intervención humana, lo que inevitablemente introduce errores y limita la escala.
La inteligencia artificial empieza a amplificar esto. Desde detectar anomalías en datos hasta anticipar comportamientos, permite pasar de un enfoque reactivo a uno predictivo.
Y con la evolución de interfaces y agentes, los datos empiezan a ser accesibles para perfiles no técnicos, reduciendo aún más la fricción entre información y decisión.
Cuándo conviene buscar apoyo profesional
Hay un punto en el que la complejidad deja de ser manejable de forma orgánica. Cuando integrar una nueva fuente toma semanas, cuando los pipelines fallan constantemente o cuando pocas personas entienden cómo funcionan los datos, el problema ya no es puntual: es estructural.
Intentar resolverlo sin experiencia suele agravar la situación. En cambio, un enfoque experto permite ordenar, simplificar y diseñar pensando en crecimiento desde el inicio.
Porque al final, escalar la arquitectura de datos no es solo un reto técnico. Es una decisión estratégica sobre cómo quieres que tu empresa crezca.
En este sentido, en BluePixel podemos llevar a tu empresa al siguiente nivel, ofreciéndote diseñar arquitecturas de datos flexibles, eficientes y seguras que crecen junto con tu producto. Desde pipelines de analítica hasta estrategias de event tracking, construimos la base para que tus datos funcionen hoy y escalen mañana. Te invitamos a explorar nuestro sitio web para conocer nuestra trayectoria y servicios.

.webp)
.webp)
