
.webp)
Many companies do not have a data problem. They have a foundation problem.
They grow, sell more, and add customers, but something starts to break. Processes become slower, numbers do not match across departments, and systems stop "talking" to one another. And almost inevitably, the same phrase comes up: "we will fix it later."
The problem is that "later" arrives at the worst possible time: when growth no longer feels like progress, but rather like friction that may be operational, technical, and financial.
That is where data architecture comes in.
It is not something you see in day-to-day operations, but it supports absolutely everything: from how decisions are made to how quickly a company can move.
At BluePixel, we bring this topic to the table for one clear reason: we have seen that the difference between companies that simply grow and companies that truly scale lies not in how much data they have, but in how they structure it.
In this article, we explain what a scalable data architecture is and, more importantly, how to tell whether your company is ready to grow without its own systems becoming an obstacle.
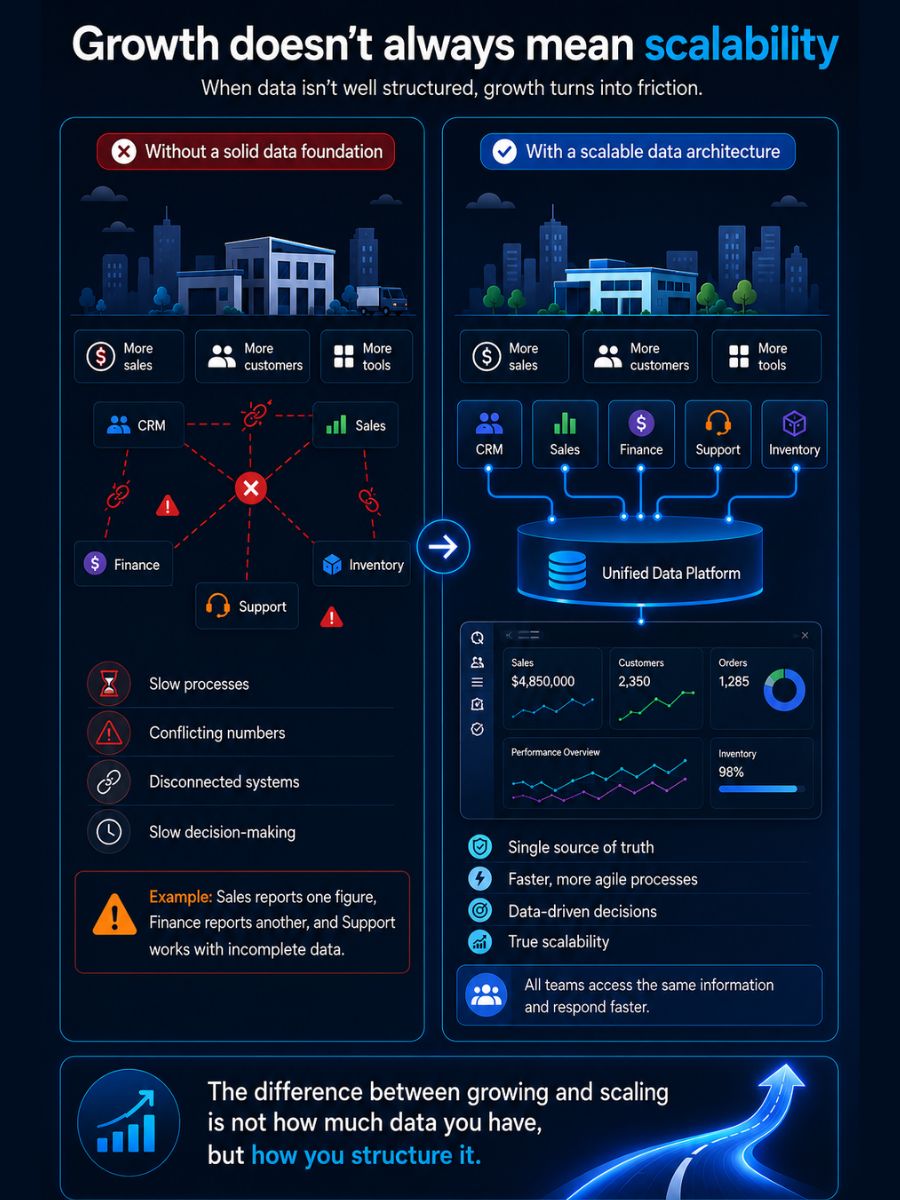
First things first: what is a scalable data architecture?
A scalable data architecture is the way you organize and connect your data so your company can grow without everything becoming slower, more expensive, or more complicated. The goal is to avoid having to rebuild your system every time you add more information, tools, or users.
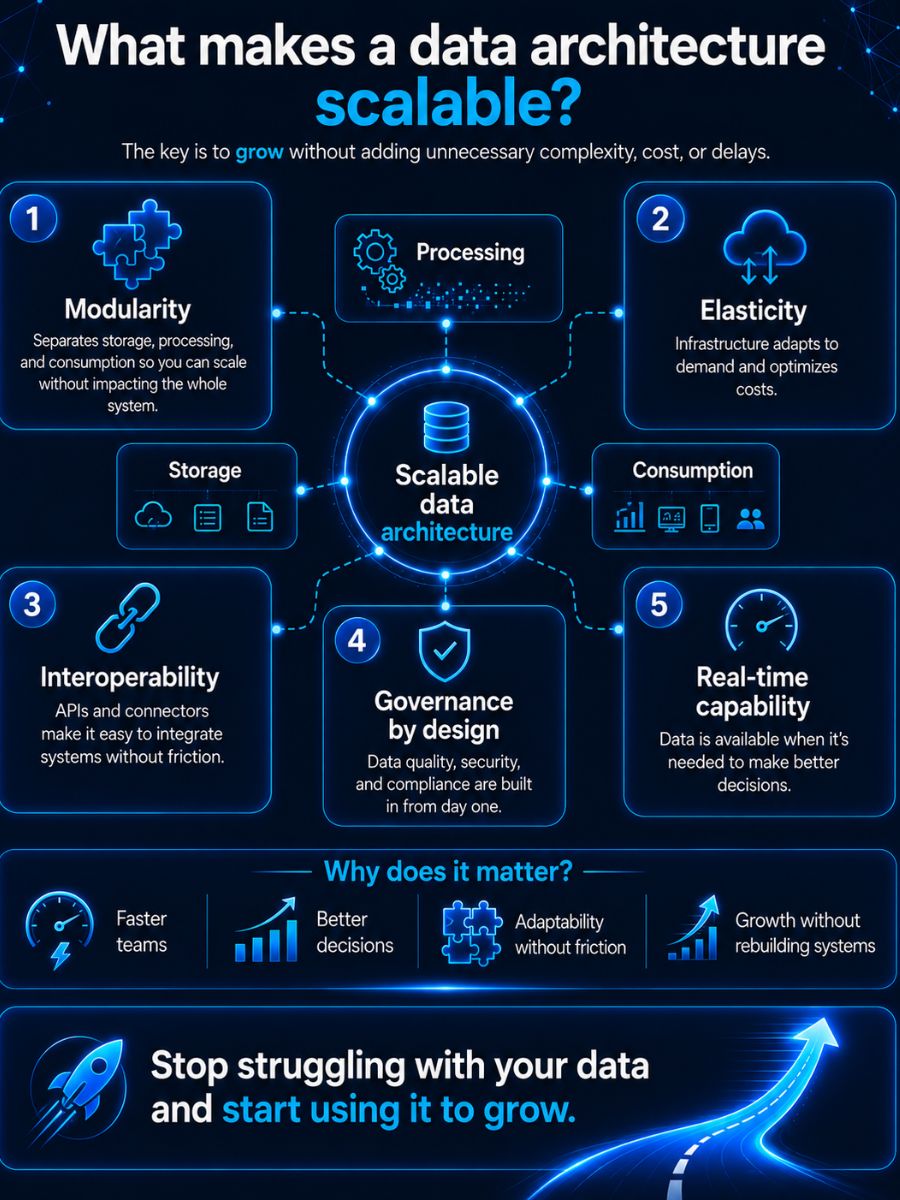
To achieve this, there are non-negotiable principles:
- Modularity
Not everything is rigidly connected. You separate data storage, processing, and consumption so you can scale or modify individual parts without affecting the entire system. - Elasticity
Your infrastructure adapts to demand. You scale when you need to and optimize costs when you do not. This is especially relevant in cloud environments. - Interoperability
Your systems can integrate without friction. APIs, connectors, and open standards prevent dependency on closed solutions or fragile integrations. - Governance by design
Quality, security, and compliance are not added later. They are built in from the beginning to prevent errors, inconsistencies, and risks. - Real-time capabilities
You do not wait days to make decisions. Data is available when you need it, not when the system allows it.
Why do these principles matter? Because when your architecture is well designed, your teams can work faster, make better decisions, and adapt without friction. You do not need to rebuild your systems every time your business changes or grows.
In short: you stop fighting your data and start using it to grow.
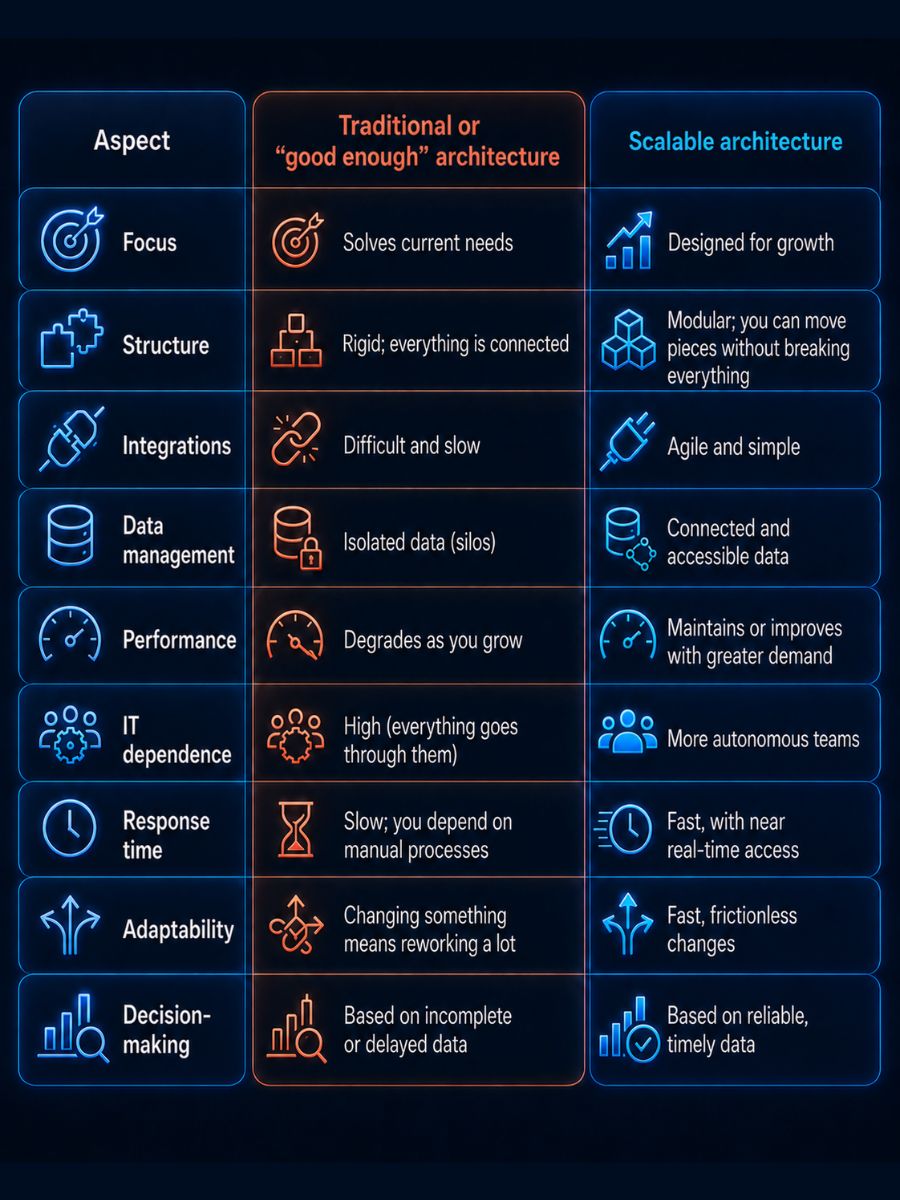
Traditional data architecture vs. scalable data architecture
Many companies operate for years with architectures that "work," but were not designed for growth. The difference between a traditional architecture and a scalable one is not always evident at first, but it becomes critical as the business evolves.
A traditional architecture is usually rigid. Systems are tightly coupled, which means that any change involves modifying multiple components. This limits flexibility and makes adapting to new needs slow and costly. By contrast, a scalable architecture is designed to evolve: it separates responsibilities, enables the integration of new technologies, and adapts without rebuilding the entire system.
The difference is also significant in terms of cost. Traditional architectures tend to generate rising expenses as complexity increases, while a modern architecture optimizes resources, especially in cloud environments where capacity can scale on demand.
Response time is another critical point. In traditional models, data is often processed with delays, limiting the business's ability to react. In a scalable architecture, access to information is much more agile, even approaching real time.
But perhaps the most important difference is the impact on the business. A traditional architecture limits decision-making speed and innovation capacity. A scalable architecture, on the other hand, enables growth, experimentation, and continuous adaptation.
The following table clearly summarizes these differences and why operating "well" is not the same as being ready to grow:
Most importantly: data architecture defines your business's capacity for growth
Data architecture defines how quickly a company can operate because it connects three key things: data, decisions, and speed. This becomes clear in very specific day-to-day situations. For example, in operations, when inventory, sales, and logistics are not synchronized, you may end up selling products you no longer have or holding back orders you could fulfill. In finance, when revenue figures do not match across systems, closing processes are delayed and decisions are postponed. In product development, if you cannot analyze user behavior because the data is fragmented, you improve what you "believe" is happening rather than what is actually happening. If data does not flow well, decisions slow down. And when decisions slow down, so does the business.
The problem is that these obstacles are rarely obvious. They are invisible bottlenecks that become part of operations: reports that must be manually consolidated every month, teams working with different versions of the same information, or departments that depend on someone else to obtain basic data. Nothing collapses completely, but everything takes longer than it should.
This is where the hidden cost of poor data architecture appears. It is not only a technology issue, but a business issue: delayed decisions, operational errors, constant rework, and missed opportunities because reacting takes too long. It is growth, but with friction at every step.
That is why, when we talk about data architecture and business growth, we are referring to a company's real ability to move with agility, adapt to change, and scale without its own data becoming an obstacle.
>> You may also be interested in reading: Futureproof, the approach that will keep you from rewriting your software every three years
But what happens if your data architecture is not ready to scale? What are the signs?
If your company is growing, your data architecture should keep pace. When it does not, very clear signs begin to appear - although they are often normalized - that something is not prepared to scale. Identifying these symptoms in time can prevent data architecture problems from becoming a structural barrier to the business.
One of the first warning signs is the time spent on your processes
If reports take days or even weeks to be ready, this is not only an efficiency issue; it is a decision-making problem. By the time you finally have the information, the context has already changed. This is often accompanied by another critical sign...
Each department manages its own "version" of the data
Finance, operations, and product report different figures in the same meeting, and the conversation shifts to "which number is correct" instead of "what do we do with it?"
It is also common for integrating new tools or data sources to become overly complex
What should take days turns into weeks or months because the systems were not designed to connect easily. This not only delays your initiatives; it also limits your ability to innovate or adapt quickly to the market.
As the company grows, another symptom scales with it: errors
Duplicate data, inconsistencies, pipeline failures, or reports that require constant manual validation. This is not a coincidence; it is a sign that the architecture is not designed to support greater volume or complexity.
And finally, one of the most critical signs: analytics stops supporting decisions
Teams end up operating based on intuition or experience because trusting the data takes too much time or effort. When you reach this point, data stops being a competitive advantage and becomes an obstacle.
All of these signs point to the same issue: it is not that data is missing, but that the foundation supporting it is not ready to scale. Detecting this in time is the first step toward correcting it before it directly affects your business growth.
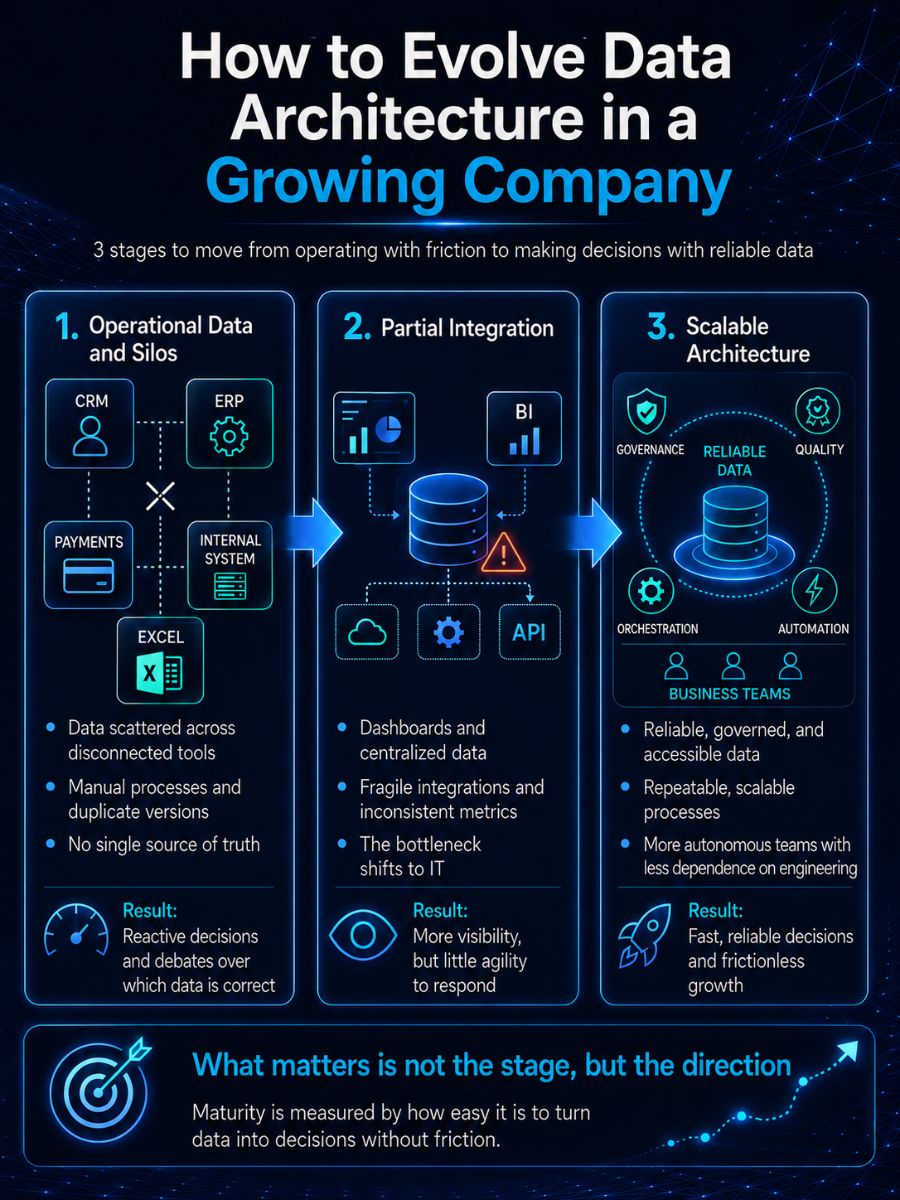
How to evolve data architecture in a growing company
Most organizations do not "design" their architecture from the start; they build it as they go, as needs arise. At first, this is entirely logical: what matters is operating, selling, and delivering. The problem is that these quick decisions, which work well in the short term, accumulate until they become structural limitations.
What is interesting is that this evolution is not chaotic. In fact, it follows a fairly clear pattern. Understanding which stage you are in not only gives you technical context, but also allows you to anticipate the next bottlenecks before they begin to directly affect operations, response times, or decision quality.
Stage 1: operational data and silos
This is where virtually every company starts. There is no intention to design an architecture; there is a need to solve day-to-day problems. Data lives in multiple disconnected tools: CRMs, ERPs, payment platforms, internal systems... and, of course, spreadsheets that end up serving as the "glue" between everything.
Each team optimizes for its own needs. Finance has its version of revenue in Excel, operations tracks its work in another system, and product measures behavior in a different tool. No one is "wrong," but there is no shared view either. The concept of a single source of truth simply does not exist.
In practice, this translates into something very specific: manual exports, files sent by email, duplicate versions of the same information, and processes that depend more on people than on systems. For example, it is common for someone to download sales data, manually cross-reference it with inventory, and then adjust figures for a report that someone else will later reinterpret in another file.
This is where the first serious problem appears: trust in the data. When each department arrives at a meeting with different figures, the conversation stops being strategic and becomes a debate about "who has the correct data."
At the business level, this forces the company to operate reactively. Decisions are made with incomplete or delayed information, and while this can work when volume is low, it stops being viable as soon as the company grows. Each new channel, product, or market does not add complexity linearly; it multiplies it.
Stage 2: partial integration
At some point, the disorder becomes unmanageable. Reports do not match, financial closings are delayed, or teams spend more time preparing data than analyzing it. This is when companies begin to "organize" their information.
BI tools such as Tableau or Power BI emerge, enabling dashboard centralization. Pipelines are also implemented using tools such as Fivetran or Talend, and data begins to be consolidated in warehouses such as Google BigQuery or Amazon Redshift.
From the outside, it appears that the problem has been solved. There are dashboards -> there is centralized data -> there is visibility. But internally, new friction begins to appear.
The pipelines work, but they are fragile. Each integration responds to a specific need, not a global design. Business logic is scattered: the same metric may be calculated differently in each dashboard. Above all, there is no clear data governance model: no one officially defines what each indicator means, who is responsible for it, or what level of quality is expected.
Something very interesting happens here: the bottleneck does not disappear; it moves.
Previously, the problem was a lack of data; now, the problem is reliance on the technical team to access it. The business wants speed, but the architecture is not designed to respond quickly.
A very common example: a department needs a new indicator to make weekly decisions. In theory, the data exists. In practice, it must be requested from engineering, prioritized in the backlog, built, validated... and by the time it finally arrives, the need has already changed or lost its urgency.
Even though data is already "centralized," it is not necessarily modeled well. Without clear semantic layers or without best practices such as structured analytics modeling, dashboards may continue to show different versions of the same reality.
At this stage, many companies believe they have already solved their data problem. In reality, they have only made it more visible.
Stage 3: scalable architecture
This is where the fundamental shift takes place. The company stops building isolated solutions and starts intentionally designing a data system, thinking not only about what it needs today, but also about how it will evolve.
Data is centralized in modern platforms such as Snowflake or in lakehouse environments such as Databricks, where storage and compute are decoupled. This makes it possible to scale without rebuilding the infrastructure every time demand increases.
Pipelines stop being stand-alone scripts and become orchestrated processes using tools such as Apache Airflow or Prefect. Extract, Load, and Transform (ELT) is adopted over Extract, Transform, and Load (ETL), taking advantage of the warehouse's processing capacity.
Data transformation is standardized with tools such as dbt (data build tool), where logic becomes version-controlled, testable, and maintainable. This completely changes the way teams work with data.
From a governance standpoint, the conversation matures. It is no longer only about having data, but about being able to trust it. Unified metric definitions, domain ownership, automated quality validations, and visibility into data lineage begin to emerge.
More advanced approaches such as data mesh or data fabric also begin to be adopted, in which business teams stop being only consumers and become responsible for their own data as products.
The impact is not only technical; it is organizational.
Teams can explore data without constantly depending on engineering. Integrating a new source stops being a long project and becomes a repeatable process. Decisions are made using reliable information and within much shorter timeframes.
And this is where the real change appears: the company stops reacting and starts anticipating. It can experiment faster, identify opportunities earlier, and adapt without friction.
What matters is not the stage, but the direction
No company starts at stage 3, and not every company needs to reach the same level of sophistication at the same time. The problem is not being at an early stage; it is remaining there when the business already requires something different.
Data architecture is not a project that gets "finished"; it is a capability that is built over time. And every decision - from working in spreadsheets to choosing between Snowflake and Databricks - has a direct impact on a company's speed, efficiency, and capacity for growth.
Ultimately, the maturity of your architecture is not measured by the tools you use, but by something much simpler: how easy it is to turn data into decisions without friction.
Key components of a scalable data architecture
A scalable data architecture is not about choosing the "right" tool, but about how all the pieces connect so data can flow smoothly. It is a complete system in which each layer fulfills a specific function and, more importantly, is designed to evolve.
It all begins with data sources, which in practice are far more diverse than they may seem. We are not only talking about internal systems such as CRMs or ERPs, but also external platforms, partner integrations, real-time events, and unstructured data such as logs or user behavior. The challenge here is not capturing data, but doing so consistently and in a usable form.
The next layer, integration and pipelines, is where many architectures fail. Poorly designed ETL or ELT processes create delays, inconsistencies, or manual dependencies. By contrast, when this layer is properly orchestrated, data flows automatically, with monitoring, traceability, and resilience in the event of failures.
Next comes storage. Choosing between a data warehouse, a data lake, or a lakehouse approach is not only a technical decision; it is a business decision. It determines how quickly you can answer questions, how much it costs to operate, and how flexible your architecture is when faced with change.
Above this is processing and analysis, where value is actually generated. This is where it is determined whether your company only understands what has already happened or can anticipate what comes next. The difference between batch and streaming, or between descriptive and predictive analytics, directly affects the speed at which the business can respond.
Finally, there is the layer that is often underestimated: data governance and quality. Without security, access control, clear definitions, and automated validations, any architecture loses credibility. And without trust in the data, there are no reliable decisions.
How can you tell whether your company is ready for a scalable data architecture?
Not every company needs to scale its architecture at the same time, but there are clear signs that it is no longer optional:
- When the business starts depending on speed to compete. If you need to react quickly, test new models, or integrate new channels, your architecture must keep pace.
- When data stops being informational and becomes operational. In other words, when day-to-day decisions depend directly on it. At that point, any delay or inconsistency has a real impact.
- Culture. When teams question decisions using data and seek metrics to validate hypotheses, the need for a solid foundation becomes unavoidable.
- Growth. If you know your volume of data, users, or complexity will increase, waiting for the system to fail is rarely the best strategy.
How to design a scalable data architecture step by step
Designing a scalable architecture is not about starting from scratch, but about making better decisions regarding what already exists.
1. It all starts with understanding the business
Which decisions need data, how often, and at what level of precision? Without this understanding, any architecture risks becoming unnecessarily complex.
2. A realistic assessment of the current state
Not from a theoretical standpoint, but from operations: where processes break, where data is lost, and where delays are generated.
From there, the design should focus on eliminating friction, not adding sophistication. Planning for growth does not mean overengineering; it means leaving room to evolve.
3. Implementation should ideally be incremental
Changing everything at the same time usually creates more problems than it solves. Advancing layer by layer, on the other hand, allows you to validate, adjust, and generate value from the early stages.
4. Finally, measure
Because an architecture that is not measured cannot be optimized, and one that is not optimized becomes obsolete more quickly than it may seem.
Avoid these common mistakes when trying to scale your data
One of the costliest mistakes is trying to get too far ahead. Implementing complex solutions without a real need creates systems that are difficult to operate and maintain.
Another mistake is growing without direction. Integrating tools without a clear vision ends up creating more silos, only now they are more sophisticated.
It is also common to see technology decisions disconnected from the business. Choosing tools because they are trending rather than because they address a real need is a quick way to accumulate technical debt.
And perhaps the most underestimated mistake is ignoring governance. Without clear rules, data loses consistency, and when that happens, the problem stops being technical and becomes strategic.
The role of automation and AI in modern data architecture
Automation is what enables everything above to work consistently. Without it, any architecture depends too heavily on human intervention, which inevitably introduces errors and limits scale.
Artificial intelligence is beginning to amplify this. From detecting anomalies in data to anticipating behavior, it enables a shift from a reactive approach to a predictive one.
And as interfaces and agents evolve, data is becoming accessible to non-technical roles, further reducing the friction between information and decision-making.
When it makes sense to seek professional support
There comes a point when complexity is no longer manageable organically. When integrating a new source takes weeks, pipelines constantly fail, or only a few people understand how the data works, the problem is no longer isolated; it is structural.
Trying to solve it without experience often makes the situation worse. By contrast, an expert approach makes it possible to organize, simplify, and design for growth from the beginning.
Ultimately, scaling data architecture is not only a technical challenge. It is a strategic decision about how you want your company to grow.
At BluePixel, we can take your company to the next level by helping you design flexible, efficient, and secure data architectures that grow with your product. From analytics pipelines to event-tracking strategies, we build the foundation your data needs to perform today and scale tomorrow. We invite you to visit our website to learn more about our experience and services.


.png)